 발전기금
발전기금



-

- 인공지능융합학과 안형진•박선영, 2023년도 한국연구재단 학술연구교수 선정
- 인공지능융합학과 안형진 학생(박사 1기, 지도교수 박은일), 박선영 학생(박사 1기, 지도교수 박은일)이 2023년도 한국연구재단 「학술연구교수(B유형)」 지원사업에 선정되었다. - 안형진 학생은 ‘지속가능한 친환경 모빌리티의 확산에 대한 사용자 경험과 수용 의사에 관한 연구’라는 연구 과제로 선정되었으며, 본교 인터랙션사이언스학과에서 ‘지속가능한 발전을 위한 지속가능 대중 교통의 사용자 수용 의도 : 혁신 확산 이론과 기술 수용 모델을 중심으로’의 주제로 석사학위를 취득했다. - 박선영 박사과정생은 '데이터마이닝과 심층 분석을 통한 COVID-19 전후 고령자 대상 헬스 리터러시 연구동향 분석'이라는 연구 과제로 선정됐다. 광운대 인공지능융합학과에서 ‘설명 가능한 인공지능 이미지 분류기가 사용자 경험에 미치는 영향’으로 석사학위를 취득했다. 이번 학술연구교수로 선정된 두 학생은 한국연구재단으로부터 향후 1년 간 2000만원의 지원금을 기반으로 안정적인 학술연구를 수행할 예정이다.
-
- 작성일 2023-08-18
- 조회수 2030
-

- DSAIL.(지도교수: 한진영), KDD2023 논문 채택
- DSAIL.(지도교수: 한진영)의 이다은(인공지능융합학과), 손세정(인공지능융합학과), 전효림(인공지능융합학과) 학생들이 연구한 논문 “Towards Suicide Prevention from Bipolar Disorder with Temporal Symptom-Aware Multitask Learning” 이 세계 최고 권위 데이터마이닝 학회인 KDD 2023 (The 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining), Applied Data Track Full papers에 채택되었습니다. 논문은 23년 8월 미국 캘리포니아 롱비치에서 발표했습니다. 본 논문은 인공지능융합학과 박사과정 및 석사과정 학생들의 협업을 통한 결과물로서 소셜 미디어 상에서 나타나는 조울증 환자들의 미래 자살 경향성을 예측하기 위해, 새로운 데이터셋과 Temporal Symptom-Aware Attention 기법을 적용한 Multitask Learning 모델을 제안하였습니다. 논문의 자세한 내용은 다음과 같습니다. [논문] Daeun Lee, Sejung Son, Hyolim Jeon, Seungbae Kim and Jinyoung Han, “Towards Suicide Prevention from Bipolar Disorder with Temporal Symptom-Aware Multitask Learning,” In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2023), Aug. 2023. [Abstract]. Bipolar disorder (BD) is closely associated with an increased risk of suicide. However, while the prior work has revealed valuable insight into understanding the behavior of BD patients on social media, little attention has been paid to developing a model that can predict the future suicidality of a BD patient. Therefore, this study proposes a multi-task learning model for predicting the future suicidality of BD patients by jointly learning current symptoms. We build a novel BD dataset clinically validated by psychiatrists, including 14 years of posts on bipolar-related subreddits written by 818 BD patients, along with the annotations of future suicidality and BD symptoms. We also suggest a temporal symptom-aware attention mechanism to determine which symptoms are the most influential for predicting future suicidality over time through a sequence of BD posts. Our experiments demonstrate that the proposed model outperforms the state-of-the-art models in both BD symptom identification and future suicidality prediction tasks. In addition, the proposed temporal symptom-aware attention provides interpretable attention weights, helping clinicians to apprehend BD patients more comprehensively and to provide timely intervention by tracking mental state progression.
-
- 작성일 2023-08-16
- 조회수 1530
-

- DSAIL Lab (지도교수: 한진영), CIKM Short paper 채택
- DSAIL Lab (지도교수: 한진영)의 정주호(인공지능융합학과), 강채원(인공지능융합학과), 윤지우(인공지능융합학과) 학생들이 연구한 논문 “SAFE: Sequential Attentive Face Embedding with Contrastive Learning for Deepfake Video Detection”이 세계 최고 권위 정보검색(Information Retrieval) 및 데이터마이닝 학회인 CIKM 2023 (32nd ACM International Conference on Information and Knowledge Management), Short papers에 채택되었습니다. 논문은 23년 10월 영국 버밍엄에서 발표될 예정입니다. 본 논문은 효과적인 딥페이크 비디오 탐지를 위해 딥페이크 비디오 영상 속에서 얼굴의 동적인 특징을 잡아낼 수 있는 SAFE (Sequential Attentive Face Embedding) 모델을 제안하였습니다. 이전의 연구들과 달리, 이 모델은 얼굴에서 나타나는 지역 정보(Local dynamics)와 전체 정보(global dynamics) 모두를 고려하여 비디오 영상의 진위여부를 파악하고, 나아가 contrastive learning을 통해 학습 과정을 최적화하였습니다. 논문의 자세한 내용은 다음과 같습니다. [논문] Juho Jung, Chaewon Kang, Jeewoo Yoon, Simon S. Woo, Jinyoung Han, “SAFE: Sequential Attentive Face Embedding with Contrastive Learning for Deepfake Video Detection,” In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM 2023), Oct. 2023. [Abstract]. The emergence of hyper-realistic deepfake videos has raised significant concerns regarding their potential misuse. However, prior research on deepfake detection has primarily focused on image based approaches, with little emphasis on video-based detection. With the advancement of generation techniques enabling intricate and dynamic manipulation of entire faces as well as specific facial components in a video sequence, capturing dynamic changes in both global and local facial features is crucial in detecting deepfake videos. This paper proposes a novel sequential attentive face embedding, SAFE, that can capture facial dynamics in a deepfake video. The proposed SAFE can effectively integrate global and local dynamics of facial features revealed in a video sequence using contrastive learning. Through a comprehensive comparison with the state-of-the-art methods on the DFDC (Deepfake Detection Challenge) dataset and the FaceForensic++ benchmark, we show that our model achieves the highest accuracy in detecting deepfake videos on both datasets.
-
- 작성일 2023-08-14
- 조회수 1288
-

- 김재광 교수 연구실, CIKM Short paper 채택
- main Lab.(지도교수: 김재광)의 고동근(인공지능융합학과), 이동준(전자전기컴퓨터공학과), 박남준(소프트웨어학과), 노경래(소프트웨어학과), 박현진(소프트웨어학과) 학생들이 연구한 논문 “AmpliBias: Mitigating Dataset Bias through Bias Amplification in Few-shot Learning for Generative Models” 이 세계 최고 권위 정보검색(Information Retrieval) 및 데이터마이닝 학회인 CIKM 2023 (32nd ACM International Conference on Information and Knowledge Management), Short papers에 채택되었습니다. 논문은 23년 10월 영국 버밍엄에서 발표될 예정입니다. 본 논문은 인공지능융합학과와 전자전기컴퓨터공학과 및 소프트웨어학과 석사과정 학생들과 소프트웨어학과 2학년 학부생의 협업을 통한 결과물로서 데이터셋에 존재하는 bias sample로 인한 인공지능 모델의 부정확함을 줄이기 위해 생성모델을 통한 Few shot learning을 하여 Debiased 모델학습 방법을 제안하였습니다. 논문의 자세한 내용은 다음과 같습니다. [논문] Donggeun Ko, Dongjun Lee, Namjun Park, Kyoungrae Noh, Hyeonjin Park and Jaekwang Kim, “AmpliBias: Mitigating Dataset Bias through Bias Amplification in Few-shot Learning for Generative Models,” In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM 2023), Oct. 2023. [Abstract]. Deep learning models have demonstrated successful performance in image classification tasks. However, these models exhibit a dependency on peripheral attributes of input data, such as shapes and colors, eventually leading to become biased towards these certain attributes, resulting in subsequent degradation of performance. To address this issue, debiasing techniques have been explored to enhance the robustness of model from biases. Recent debiasing techniques improve biased classifier f_b by reweighting technique or augment the biased dataset to mitigate bias. In this paper, we focus on the latter approach, presenting AmpliBias, a novel framework that tackles dataset bias by leveraging generative models to amplify bias and facilitate the learning of debiased representations of the classifier. Our method involves three major steps. First, we train a biased classifier, f_b, using a biased dataset and extract top-K biased-conflict samples. Subsequently, we train a generator on a bias-conflict dataset composed solely of the top-K samples to learn the distribution of bias-conflict samples. Finally, we re-train the classifier with the new debiased dataset, allowing the biased classifier to competently learn debiased representation. Extensive experiments validate that our proposed method effectively debiases the biased classifier.
-
- 작성일 2023-08-11
- 조회수 1099
-

- 인공지능융합학과 김동재·박진희, 정보통신기획평가원 주최 캐나다 토론토대 AI융합교육 프로그램 선발
- 인공지능융합학과 김동재 학생(석사 2기, 지도교수 박은일), 박진희 학생(석사 2기, 지도교수 박은일)이 과학기술정보통신부, 정보통신기획평가원(IITP)이 주최하는 캐나다 토론토대( University of Toronto ) AI 융합 교육 프로그램에 선발되었다. 정보통신기획평가원에서 주최하는 AI 융합교육과정은 해외 최고 수준 대학에 맞춤형 AI 교육과정을 개설하고, 대학원생을 파견·교육하여 디지털 혁신기술 분야 고급 인재 육성을 목적으로 한다. 23년 12월 말부터 24년 6월까지의 6개월(코스웍 4개월, AI프로젝트 2개월) 이후 24년 8월 최종 결과 보고를 끝으로 프로그램이 마무리된다. 인당 5,500만원 상당의 교육비, 체재비, 항공료, 여행자 보험 등을 지원받아 진행될 것이다.
-
- 작성일 2023-08-08
- 조회수 1268
-

- 오하영 교수 연구실, CIKM2023 컨퍼런스 논문 Accept
- 오하영 교수연구실 LAMDA Lab에서 발표한 Can a chatbot be useful in childhood cancer survivorship? Development of a chatbot for survivors of childhood cancer 논문이 CIKM (ACM International Conference on Information and Knowledge Management)의 Poster 세션에 Accept 되었다. 논문의 내용은 소아암 생존자를 위한 정보 전달 및 공감형 챗봇 개발에 관한 연구로 소아암 생존자 관련 데이터 구축 및 도메인 학습 기법을 활용하여 소아암 생존자의 특성을 고려한 챗봇 개발을 소개한다. CIKM (ACM International Conference on Information and Knowledge Management)는 1992년 첫 개체되어 올해로 32회를 맞은 데이터베이스, 정보검색(Information retrieval), 지식관리(Knowledge management) 분야의 권위 있는 학회로 오는 10월 21일부터 10월 25일까지 영국에서 개최된다. CIKM 2023(https://uobevents.eventsair.com/cikm2023/)
-
- 작성일 2023-08-08
- 조회수 1516
-

- 인공지능융합학과 김지혜 평택시의회 ‘돌봄의 미래를 말하다’라는 주제로 강연
- 평택시의회 돌봄취약계층을 위한 사회안전망구축 연구회는 27일 ‘돌봄의 미래를 말하다’라는 주제로 강연회를 개최했다. 이날 김지혜 강사(성균관대 인공지능융합학과 박사과정)가 혁신적인 노인 돌봄케어를 위한 ICT(정보 통신 기술)의 역할과 국내외 사례에 대한 강연을 진행했다. 연구회 회원들은 고령화 대응을 위한 ICT 기술과 국내외 ICT 기반 돌봄 사업의 동향 및 안전, 건강․의료, 사회참여․여가 등 일상생활의 각 분야에 ICT가 실제 적용된 사례를 살펴보고, 평택시 노인 돌봄 서비스에 접목할 수 있는 방안과 고려사항 등에 대해 폭넓은 의견을 나눴다.
-
- 작성일 2023-07-25
- 조회수 1052
-

- 인공지능융합학과 이다은 2023년도 한국 이공계 여성대학원생 미국 연수 프로그램 과제 선정
- [사진] 인공지능학과 이다은 학생 과학기술정보통신부에서 실시한 2023년도「한국 이공계 여성대학원생 미국 연수 프로그램」에 성균관대 이다은 대학원생의 "치매 조기 진단을 위한 다국어 멀티모달 인공지능 모델 개발"과제가 선정되었다. 과학기술정보통신부에서는 매년 「한국 이공계 여성대학원생 미국 연수 프로그램」을 통해 한국과 미국 양국 간 인력교류 사업을 통해 여성 신진연구자의 연구 활동 및 이공계 분야 진출을 촉진하고, 양국 간 공동 R&D프로젝트 참여를 통해 연구역량 증진과 해외 연구 네트워크 구축 기회를 제공하고 있다. 「한국 이공계 여성대학원생 미국 연수 프로그램」은 항공료와 6개월 체재비를 포함하여 1500만원을 지원한다.
-
- 작성일 2023-07-19
- 조회수 1031
-

- 류은석 교수, 제33회 과학기술우수논문상 수상
- 본교 실감미디어공학과 류은석 교수는 2023년 7월 6일 한국과학기술단체총연합회 주관 제33회 과학기술우수논문상을 수상하였다. 류은석 교수는 한국방송·미디어공학회 대표로 수상하였고, 방송공학회논문지 제27권 제6호에 게재된 '대형 가상현실 공연장을 위한 360도 비디오 스트리밍 시스템' 이라는 제목의 논문으로 수상하였다. 과학기술우수논문상은 한국과학기술단체총연합회에서 수여하는 국내 과학기술계 최고 권위의 학술상 중 하나로, 1991년부터 수여된 바 있다.
-
- 작성일 2023-07-17
- 조회수 757
-
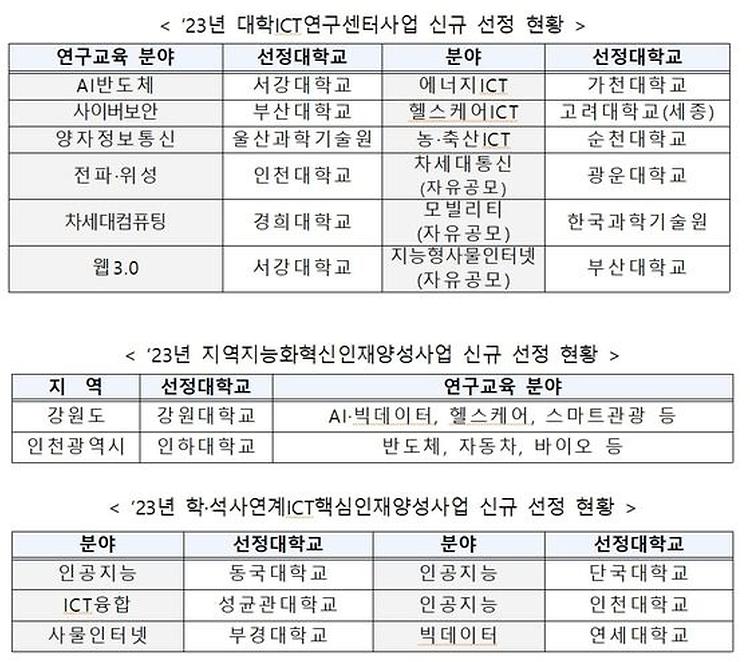
- 성균관대 학/석사연계ICT핵심인재양성사업 ICT융합부문 선정
- 성균관대, 2023년 ICT핵심인재 양성 사업 선정 - 일반대학원 인공지능융합학과, 과기부 학석사연계ICT핵심인재양성 지원사업 선정 과학기술정보통신부와 정보통신기획평가원은 2023학년도 학석사연계ICT핵심인재양성 지원 사업에 성균관대를 포함한 6개 대학을 선정했다고 밝혔다. ‘학석사연계ICT핵심인재양성’은 기존 ICT혁신인재양성4.0의 확장 사업으로, 일방향적인 교과 수업방식에서 탈피하여 기업과 공동으로 기업 현장문제 기반의 연구·교육과정(PBL, Problem Based Learning)을 운영하여 실전 문제해결 역량을 갖춘 ICT 분야 석·박사 인재를 양성하는 사업이다. 이번 사업 선정으로 우리 대학은 향후 5년 간 엔터테인먼트 데이터 사이언스 연구 및 교육 과정 운영을 통해 문제해결 중심의 ICT 석박사 전문 인재를 매년 10명 이상 배출할 예정이다. 특히, 9개의 엔터테인먼트 전문 기업과 기관 실무자의 참여를 통해 산업 문제 해결 중심의 연구와 교육을 수행할 계획이다. 해당 사업 선정으로 인하여 우리 대학은 기존의 사업단*과 함께, 2개의 ICT핵심인재양성 사업을 운영하게 된다. * ICT 서비스 기획 인력양성을 위한 사용자 중심 인공지능 교육 과정 성균관대(ICT융합부문)의 과제내용은 엔터테인먼트 데이터 사이언스 연구교육과정 개발 및 운영이며 게임/XR 분야 AI/데이터 활용 및 산업친화형 교육과정 개발 운영을 통해 PBL기반 엔터테인먼트 데이터사이언스 실전 문제를 해결할 수 있는 전문 인재 양성한다는 계획이다. 성균관대(ICT융합부문)의 연구책임자는 인공지능융합학과 박은일 교수, 참여교수로는 인공지능융합학과 한진영, 김재광, 류은석, 송하연 교수, 소프트웨어학과 이호준 교수가 선정되었다. 사업책임자 박은일 교수는 “엔터테인먼트 산업 내 데이터 사이언스 전문 인재 수요에 대응할 수 있는 전문가를 양성하겠다”고 포부를 밝혔다.
-
- 작성일 2023-06-22
- 조회수 747